この日記は、RDBMS-GIS(MySQL,PostgreSQLなど) Advent Calendar 2020 の24日目の記事です。
はじめに
先日の日記で、LINESTRING や MULTIPOINT にある点の要素を、POINTのデータ群として得る方法のアイデアを紹介しました。
MySQLの空間データ型の変換(1)~MULTIPOINTやLINESTRINGからPOINTを得る~
今回は、その続編として、POINT型のデータ群をつなげて LINESTRING にする方法のアイデアについて書きたいと思います。正直なところ「ちからワザ」です。とりあえずこのようなやり方で実現は可能だぞという、ひとつの思考実験的なものとしてお読みいただければと思います。

実験データの用意
GEOMETRY型のカラムを持つ、以下のテーブルを作成し、データを投入します。とりあえず3件(3点)
CREATE TABLE t1 (id integer, p geometry, odr integer, cat varchar(1))
INSERT INTO t1 VALUES (1, ST_GeomFromText('POINT(1 3)'), 10, "A"); INSERT INTO t1 VALUES (2, ST_GeomFromText('POINT(2 2)'), 20, "A"); INSERT INTO t1 VALUES (3, ST_GeomFromText('POINT(3 4)'), 30, "A");
この3つの点を、odr列の値の順につなげて LINESTRING 型の結果を得ることを目標とします。
思考実験
処理のイメージとしては、
- 必要なPOINT型の行を GROUP BY でひとかたまりとして扱って
- SUM() 関数みたいな感じで、例えば GROUP_LINESTRING()みたいな集約関数を使って LINESTRING にする(その際ORDERも指定する)
なんてことができたらいいなと考えるわけですが、残念ながらそんなグルーピング関数はありません。
仕方がないので、作戦変更し、POINT型の集合を得た後、自力で LINESTRING にすることを考えてみます。
LINESTRING にするためには、ST_GeomFromText('LINESTRING(1 1, 2 2, 3 3, 4 4)') のように、WKT文字列を構成してから ST_GeomFromText() で変換すれば良いわけです。
3点をLINESTRINGにしてみる
ということで、先ほどの3つのPOINTをLINESTRINGに変換してみたのが以下のSQL。
GROUP_CONCATを使って、抽出したPOINTのX,Yの集合をコンマ区切りでつなげます。GROUP_CONCAT の ORDER BY を使うことで、点の順序を指定できます。
SELECT ST_AsText( ST_GeomFromText( CONCAT("LINESTRING(", GROUP_CONCAT(ST_X(p), " ", ST_Y(p) ORDER BY odr), ")"))) a FROM t1 WHERE cat="A";
+-------------------------+ | a | +-------------------------+ | LINESTRING(1 3,2 2,3 4) | +-------------------------+ 1 row in set (0.00 sec)
なんだかそれっぽいLINESTRINGが得られました。これ、単に文字列結合した結果が表示されているわけではなくて、一旦Geomに変換後、改めて表示用に ST_AsText() してるんですからね。
念のため、ORDER BY がちゃんと効いていることを確認するために、ORDER BY の DESC の動作も見ておきましょう。
mysql> SELECT ST_AsText( -> ST_GeomFromText( -> CONCAT("LINESTRING(", GROUP_CONCAT(ST_X(p), " ", ST_Y(p) ORDER BY odr DESC), ")"))) a -> FROM t1 -> WHERE cat="A"; +-------------------------+ | a | +-------------------------+ | LINESTRING(3 4,2 2,1 3) | +-------------------------+
期待通りに ORDER BY が働いているようです。
このクエリの制限と回避方法
とりあえず力業で、やりたいことを実現させましたが、実はこのやり方は万能ではありません。
どこに落とし穴があるのか。それは GROUP_CONCAT() の文字数制限です。
デフォルトでは、GROUP_CONCATは 1024文字までを扱うことができます。この値は変更することができるので、実際に、先ほどのSQLのGROUP_CONCAT() が出力することになりそうな最大のサイズを見積もった上で、group_concat_max_len を設定すると良いでしょう。
mysql> show variables like 'group_con%'; +----------------------+-------+ | Variable_name | Value | +----------------------+-------+ | group_concat_max_len | 1024 | +----------------------+-------+
もう少し点数の多い例でも確認
3点だけではやや物足りないので、もう少し点数の多いPOINTを、LINESTRINGにしてみましょう。以下のSQLでデータを追加します。
INSERT INTO t1 VALUES (10, ST_GeomFromText('POINT(1 2)'), 21, "T"); INSERT INTO t1 VALUES (11, ST_GeomFromText('POINT(1 3)'), 25, "T"); INSERT INTO t1 VALUES (12, ST_GeomFromText('POINT(1 4)'), 31, "T"); INSERT INTO t1 VALUES (13, ST_GeomFromText('POINT(3 0)'), 12, "T"); INSERT INTO t1 VALUES (14, ST_GeomFromText('POINT(3 2)'), 16, "T"); INSERT INTO t1 VALUES (15, ST_GeomFromText('POINT(3 3)'), 24, "T"); INSERT INTO t1 VALUES (16, ST_GeomFromText('POINT(3 4)'), 29, "T"); INSERT INTO t1 VALUES (17, ST_GeomFromText('POINT(4 6)'), 33, "T"); INSERT INTO t1 VALUES (18, ST_GeomFromText('POINT(5 2)'), 55, "T"); INSERT INTO t1 VALUES (19, ST_GeomFromText('POINT(5 3)'), 50, "T"); INSERT INTO t1 VALUES (20, ST_GeomFromText('POINT(5 4)'), 36, "T"); INSERT INTO t1 VALUES (21, ST_GeomFromText('POINT(5 0)'), 60, "T"); INSERT INTO t1 VALUES (22, ST_GeomFromText('POINT(7 2)'), 53, "T"); INSERT INTO t1 VALUES (23, ST_GeomFromText('POINT(7 3)'), 39, "T"); INSERT INTO t1 VALUES (24, ST_GeomFromText('POINT(7 4)'), 34, "T");
先ほどうまくいったクエリを少し改良して、、、、、
mysql> SELECT ST_AsText( -> ST_GeomFromText( -> CONCAT("LINESTRING(", GROUP_CONCAT(ST_X(p), " ", ST_Y(p) ORDER BY odr), ")"))) a -> FROM t1 -> WHERE cat="T"; +-------------------------------------------------------------------------+ | a | +-------------------------------------------------------------------------+ | LINESTRING(3 0,3 2,1 2,3 3,1 3,3 4,1 4,4 6,7 4,5 4,7 3,5 3,7 2,5 2,5 0) | +-------------------------------------------------------------------------+
LINESTRING が得られました。目的達成です! でも文字だけの出力結果を見ても何だかよく分からないので、やっぱりビジュアルに表示してみたいですね。MySQL Workbench を使って見てみましょう。
その際、クエリ結果を人間が見るわけじゃないので、ST_AsText()は外します。
SELECT ST_GeomFromText( CONCAT("LINESTRING(", GROUP_CONCAT(ST_X(p), " ", ST_Y(p) ORDER BY odr), ")")) a FROM t1 WHERE cat="T";
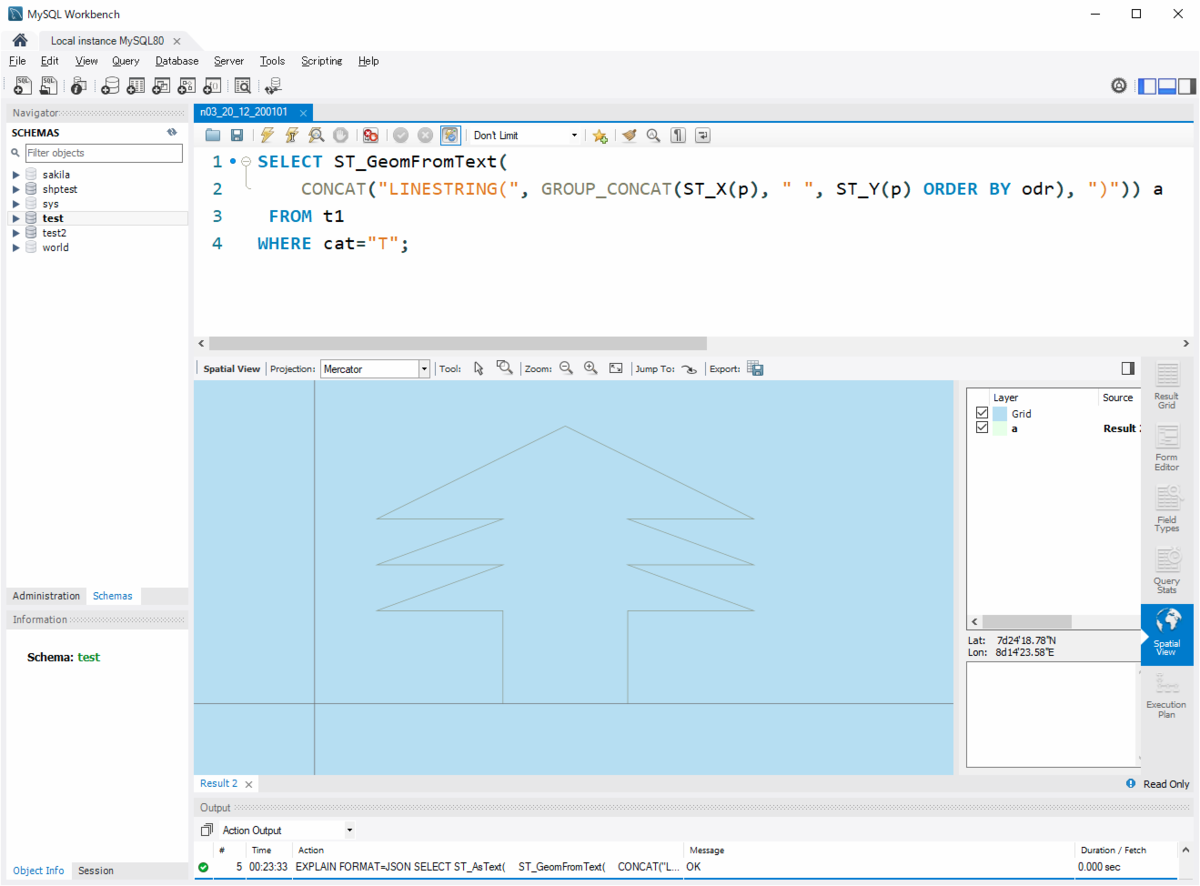
メリークリスマス! Merry Xmas!!