先日参加した「MyNA(日本MySQLユーザ会) 望年LT大会2025@新宿」にて、(要約すると)「Spatial Indexなんかよりも緯度経度で検索したほうが、ずっと速いよ!」という発表を聞かせていただきました。
MySQLのSpatial Indexは遅いのか?
今回設定されたケースでは、「緯度経度での検索」が最速なのは、言われてみれば納得感はあります。何と言ったって、緯度と経度の数字の大小関係だけで対象エリアが特定できるのだから、余計なことをしない(プリミティブな数値型だけで評価できる)方法が最速になるんじゃないかな。
・・・・という仮説を、会場でもお話させていただきました。
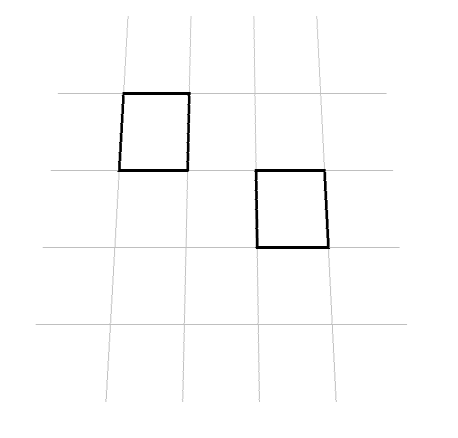
空間インデックスが効果的に使えるのは、(今回のトライを活かすとすると)こんな形とか、あるいはもっと複雑なポリゴンとか、範囲(中心点からの距離)とかの時なのかなぁと思いました。

GeoHashの計測について
GeoHashを使ったSQLを見てみると、結局 lat/lon の最大最小を使って絞り込んでいることに気づきました。これ、geohash列が条件に加わった分、緯度経度の絞り込みと比べて無駄な処理をするだけなのではないでしょうか。
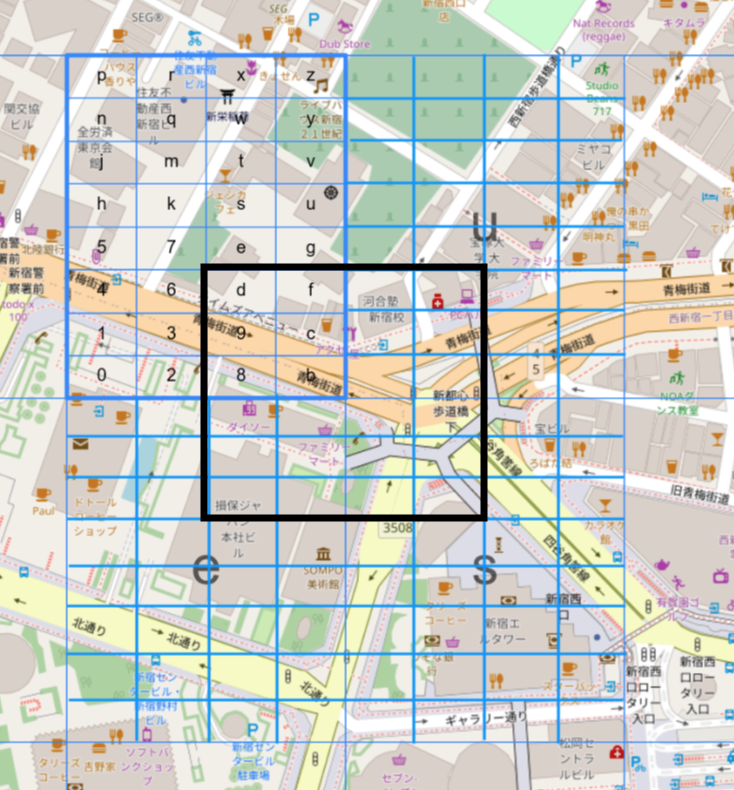
GeoHashというのは「隣接」の概念には非常に弱くて、範囲の絞り込みにもあまり適切でない仕組みだと理解しています。例えば下図の黒枠線のような範囲が対象となる場合、左下GeoHash値は xn774cet(略して Xcetとします)、右上は xn774cu6(同 Xcu6)となります。 Between 'Xcet' AND 'Xcu6' には 'Xc[f-u][.]' の範囲が含まれていますから、この図で言うと黒い枠線内のみでなく Xcs. に相当する「s」の全領域も対象に含まれてしまい、あまり効果的に絞り込めているとは言えないですよね(本当に大きな範囲から、無駄を承知で少しでも絞り込みを、、、という時に生きてくる可能性はあると思いますが)。
(ちょっとわかりにくい説明だったので補足すると、左下Xcet は正しいけれども、その上にあるXcgなんとか、をはじめとして、Xchなんとか、Xciなんとか、、といった全然関係ないエリアにもマッチしているということです)
一方で、「GeoHashに24桁も要るのか問題」というのはあり、この桁数がパフォーマンスに影響を与えている可能性があるのでは、とも思いました。
p0のpointについて
会場にて「すべてのクエリの結果が完全には一致しなかった」という話を聞かせていただいて考えていたのですが、 p0 列はオリジナルの緯度経度値を必ずしも保存できていませんね。GeoHashに24桁も使っているので現実的には元の値に戻る気もしますが、値の維持には、単に元の4326の値を ST_SRID()でデカルトにするのが確実かと思います。
GeoHashも結局緯度経度で絞り込んでいることを考えると、すべてのクエリで同じ件数が得られるべきと考えるのが自然かなぁ、、と思いました。
ST_GeomFromText()のオーバヘッド?
クエリをよく見てみると、lat/lon の時は数字をそのままクエリに供しているのに対して、GeoHashもSpatial Indexも、ST_GeomFromText()やST_Geohash()関数で都度変換処理を行っていますね。これらの関数が著しく遅いものだとは思っていませんが、もしかすると大量に処理したときにはこの関数のオーバヘッドが蓄積されたものが差に表れているのでは? とも思いました。